DDL
DDL–操作数据库
- 查询数据库
show database;
- 创建数据库
create database 数据库名称;
判断,如果不存在则创建
create database if not exists 数据库名称;
- 删除
drop database 数据库名称;
判断,如果存在就删除
drop database if exists 数据库名称;
- 使用数据库 查看当期那使用的数据库
select database();
使用数据库
use 数据库名称;
DDL–操作表
查询表
查询当前数据库下所有表名称
show tables;
查询表结构
desc 表名称;
创建表
create table 表名(
字段名1 数据类型1,
字段名2 数据类型2,
字段名3 数据类型3,
...
字段名n 数据类型n
);
数据类型看这个:[[SQL的数据类型]]
删除表
drop table 表名称;
删除表时判断表是否存在
drop table if exists 表名称;
修改表
- 修改表名
alter table 表名 rename to 新的表名;
- 添加一列
alter table 表名 add 列名 数据类型;
- 修改数据类型
alter table 表名 modify 列名 新数据类型;
- 修改列名和数据类型
alter table 表名 change 列名 新列名 新数据类型;
- 删除列
alter table 表名 drop 列名;
DML
添加数据
- 给指定列添加数据
insert into 表名(列名1,列名2,...) values(值1,值2,...);
- 给所有列添加数据
insert into 表名 values(值1,值2,...);
- 批量添加数据
insert into 表名(列名1,列名2,...) values(值1,值2,...),(值1,值2,...),(值1,值2,...),...;
-- 两种都可以
insert into 表名 values(值1,值2,...),(值1,值2,...),(值1,值2,...),...;
修改数据
update 表名 set 列名1=值1, 列名2=值2,...[where 条件]; -- 多个条件中间用and
==注意:修改语句中如果不加条件,则将所有数据都修改==
删除数据
delete from 表名 [where 条件];
==注意:删除语句中如果不加条件,则将所有数据都修改==
DQL
基础查询
- 查询多个字段
select 列名1,列名2,... from 表名 -- 要查询所有列可以用*
- 去除重复记录-distinct
select distinct 字段列表 from 表名;
- 起别名-as(可以省略,中间空一个空格即可)
select 列名1 as 别名1,列名2 别名2,... from 表名;
条件查询(where)
 演示:
表结构和数据:
演示:
表结构和数据:
-- 创建学生表
CREATE TABLE students (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
gender ENUM('男', '女') NOT NULL,
english_score DECIMAL(5,2),
math_score DECIMAL(5,2)
);
-- 插入数据
INSERT INTO students (name, gender, english_score, math_score) VALUES
('张三', '男', 85.5, 92.0),
('李四', '男', 78.0, 88.5),
('王五', '男', 92.5, 76.0),
('赵六', '女', 88.0, 94.5),
('钱七', '女', 76.5, 82.0),
('孙八', '男', 91.0, 89.5),
('周九', '女', 84.5, 77.0),
('吴十', '男', 79.0, 85.5),
('郑十一', '女', 87.5, 91.0),
('王十二', '男', 83.0, 79.5),
('李十三', '女', 90.5, 86.0),
('张十四', '男', 75.5, 83.5),
('刘十五', '女', 89.0, 95.5),
('陈十六', '男', 82.5, 78.0),
('杨十七', '女', 94.0, 88.5),
('黄十八', '男', 77.5, 84.0),
('赵十九', '女', 86.5, 92.5),
('钱二十', '男', 81.0, 87.5),
('孙二十一', '女', 93.5, 80.0),
('周二十二', '男', 80.5, 90.0),
('王三', '男', 85.5, 80.0),
('哈三', '男', 85.5, null);
查询语句:
-- 英语成绩大于80
select *from students where english_score > 80;
-- 数学成绩小于80
select *from students where math_score<80;
-- 数学成绩大于等于 77
select *from students where math_score>=77;
-- 数学成绩小于等于 77
select *from students where math_score<=77;
-- 数学成绩等于 77
select *from students where math_score=77;
-- 数学成绩不等于 77
select *from students where math_score!=77;
select *from students where math_score<>77;
-- 数学成绩在80到90之间的
select *from students where math_score>=80 and math_score<=90;
select *from students where math_score between 80 and 90;
-- 数学成绩为82或85.5或77
select *from students where math_score=82 or math_score=77 or math_score=85.5;
select *from students where math_score in(82,85.5,77);
-- 数学成绩为null
select *from students where math_score is null;
-- 数学成绩不为null
select *from students where math_score is not null;
-- 数学成绩为76并且英语成绩为92.5
select *from students where math_score=76 and english_score=92.5;
-- 数学成绩为76或者英语成绩为92.5
select *from students where math_score=76 OR english_score=92.5;
-- 查询姓张的同学
select *from students where name like '张%';
-- 查询名字第二个字是'十'的同学
select *from students where name like '_十%';
-- 查询名字中包含'四'的同学
select *from students where name like '%四%';
排序查询(order by)
select 字段列表 from 表名 order by 排序字段名1[排序方式1] ,排序字段名2 [排序方式2] ...;
排序方式: asc:升序排列(默认值) desc:降序排列 演示: 表结构和数据同上 查询语句:
-- 按数学成绩升序排列
select *from students order by math_score;
select *from students order by math_score asc;
-- 按英语成绩降序排列
select *from students order by english_score desc;
-- 按数学成绩降序排列,如果数学成绩一样则按照英语成绩升序排列
select *from students order by math_score desc,english_score;
==如果有多个排序条件,当前边的条件值一样时,才会根据第二条条件进行排序==
聚合函数
-
将一列数据作为整体,进行纵向计算
-
分类:
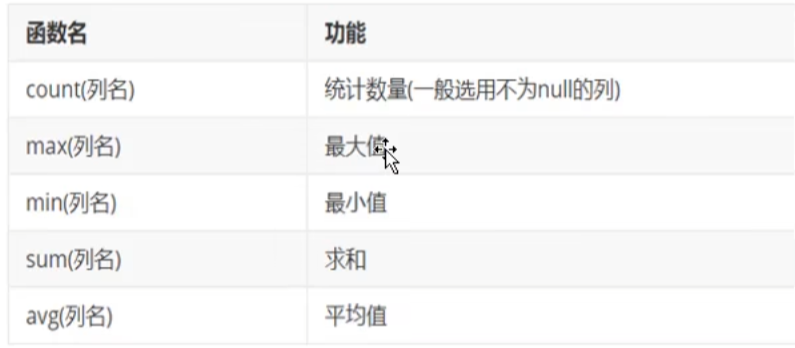
-
代码演示
select 函数名(列名) from 表名;
- 案例同上
-- 统计一共有多少个学生
select count(*) as 人数 from students;
-- 数学成绩最高分
select max(math_score) as 数学最高分 from students;
-- 英语成绩最低分
select min(english_score) as 英语最低分 from students;
-- 所有人英语加在一起的分数
select sum(english_score) as 英语总分 from students;
-- 英语平均分
select avg(english_score) as 英语平均分 from students;
分组查询
select 字段列表 from 表名 [where 分组前条件限定] group by 分组字段名 [having 分组后条件过滤];
==注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义==
where和having区别:
- 执行时机不一样:where是分组之前进行的限定,不满足where条件,则不参与分组,而having是分组之后对结果进行过滤。
- 可判断的条件不一样:where不能对聚合函数进行判断,having可以。
执行顺序:where>聚合函数>having
案例同上
-- 查询男女各自的数学平均分
select gender,avg(math_score) from students group by gender;
-- 查询男女各自的数学平均分,以及各自人数
select gender,avg(math_score),count(gender) from students group by gender;
-- 查询男女各自的数学平均分,以及各自人数,要求分数低于80分的不参与分组
select gender,avg(math_score),count(gender) from students where math_score>=80 group by gender;
-- 查询男女各自的数学平均分,以及各自人数,要求分数低于80分的不参与分组,分组之后人数大于8
select gender,avg(math_score),count(gender) from students where math_score>=80 group by gender having count(*)>8;
分页查询
select 字段列表 from 表名 limit 起始索引,查询条目数;
起始索引:从0开始
案例同上
-- 从0开始查询,查询3条数据
select * from students limit 0,3;
-- 每页显示3条数据,查询第1页数据
select * from students limit 0,3;
-- 每页显示3条数据,查询第2页数据
select * from students limit 3,3;
-- 每页显示3条数据,查询第3页数据
select * from students limit 6,3;
-- 计算公式:起始索引=(当前页码-1) * 每页显示的条数
约束
-
约束概念:
- 约束是作用于表中列上的规则,用于限制加入表的数据
- 约束的存在保证了数据库中数据的正确性,有效性和完整性
-
约束的分类
 auto_increment:自增长
auto_increment:自增长 -
案例
-- 部门表(主表)
create table dept(
id int PRIMARY key auto_increment,
dep_name char(3) not null,
addr varchar(10) not null
);
-- 员工表(从表)
create table emp(
id int primary key auto_increment, -- 员工id,主键且自增长
ename varchar(50) UNIQUE not null, -- 员工姓名,非空并且唯一
joindate date not null, -- 入职信息,非空
salary double(7,2) not null, -- 工资,非空
bonus double(7,2) DEFAULT 0, -- 奖金,如果没有奖金默认为0
dept_id int not null, -- 部门id,部门id为外键
CONSTRAINT fk_emp_dept FOREIGN KEY(dept_id) REFERENCES dept(id)
);
外键约束
create table 表名(
列名 数据类型,
...
[constraint] [外键名称] foreign key(外键列名) references 主表(主表列名)
);
-- 建完表之后添加外键约束
alter table add constraint 外键名称 foreign key(外键字段名) references 主表名称(主表列名称);
-- 删除约束
alter table 表名 drop foreign key 外键名称;
多表查询
内连接:相当于A B交集的数据
-- 隐式内连接
select 字段列表 from 表1,表2 ... where 条件;
-- 显示内连接
select 字段列表 from 表1,[inner] join 表2 on 条件;
外连接
-- 左外连接:相当于查询A表中所有数据和交集部分数据
select 字段列表 from 表1 left [outer] join 表2 on 条件;
-- 右外连接:相当于查询B表中所有数据和交集部分数据
select 字段列表 from 表1 right [outer] join 表2 on 条件;
子查询
子查询根据结果不同,作用不同:
-- 单行单列:作为条件值,使用= != > < 等进行条件判断
select 字段列表 from 表 where 字段名 = (子查询);
-- 多行单列:作为条件值,使用in等关键字进行条件判断
select 字段列表 from 表 where 字段名 in (子查询);
-- 多行多列:作为虚拟表
select 字段列表 from (子查询) from(子查询) where 条件;
事务
一种机制,包含了一组数据库命令,要么同时成功,要么同时失败
-- 开启事务
start transaction;
或者
begin;
-- 提交事务
commit;
--回滚事务
rollback;
案例:
create table yinHang(
id int primary key auto_increment,
name varchar(10),
money int
);
insert into yinHang(name,money) values('张三',1000),('李四',1000);
begin;
UPDATE yinHang set money=money-500 where name='李四';
update yinhang set money=money+500 where name='张三';
commit;
rollback;
事务四大特征
 MySql事务默认自动提交
MySql事务默认自动提交
select @@autocommit;
-- 1自动提交 0手动提交
--修改事务提交方式
set @@autocommit = 0;
增加
concat() 字符串拼接